OpenVINO 2024.2 新功能
更多 Gen AI 覆盖和框架集成,以最大限度地减少代码更改。
- Llama 3 针对 CPU、内置 GPU 和独立 GPU 进行优化,以提高性能并提高内存使用效率。
- 支持 Phi-3-mini,这是一组 AI 模型,利用小型语言模型的强大功能实现更快、更准确、更具成本效益的文本处理。
- OpenVINO 现已启用 Python 自定义操作,让 Python 开发人员可以更轻松地编写自定义操作,而无需使用 C++ 自定义操作(也受支持)。Python 自定义操作使用户能够将自己的专门操作实现到任何模型中。
- 笔记本扩展,以确保更好地覆盖新型号。添加了值得注意的笔记本:DynamiCrafter、YOLOv10、带有 Phi-3 的 Chatbot 笔记本和 QWEN2。
更广泛的大型语言模型 (LLM) 支持和更多的模型压缩技术。
- 将 4 位权重压缩的 GPTQ 方法添加到 NNCF 中,以实现更高效的推理并提高压缩 LLM 的性能。
- 显著提高 LLM 性能并降低内置 GPU 和独立 GPU 的延迟。
- 在基于 AVX2(第 13 代英特尔® 酷睿™ 处理器)和 AVX512(第 3 代英特尔® 至强® 可扩展处理器)的 CPU 平台上,FP16 权重 LLM 的第 2 个令牌延迟和内存占用显著改善,尤其是对于小批量而言。
更高的可移植性和性能,可以在边缘、云端或本地运行 AI。
- 模型服务增强功能:
- 预览:OpenVINO 模型服务器 (OVMS) 现在支持与 OpenAI 兼容的 API 以及连续批处理和 PagedAttention,在为许多并发用户提供 LLM 时,可以显著提高并行推理的吞吐量,尤其是在 Intel® Xeon® 处理器上。
- 除了动态形状支持外,Triton Server 的 OpenVINO 后端现在还支持内置 GPU 和独立 GPU。
- 通过 torch.compile OpenVINO 后端集成 TorchServe,以便轻松部署模型、配置多个实例、进行模型版本控制和维护。
- 预览:添加了 Generate API,这是一个简化的 API,仅需几行代码即可使用大型语言模型生成文本。该 API 可通过新推出的 OpenVINO GenAI 软件包获得。
- 支持 Intel Atom® 处理器 X 系列。有关更多详细信息,请参阅 系统要求。
- 预览:支持英特尔® 至强® 6 处理器。
OpenVINO™ Runtime
Common
- 现在支持使用 UINT2、UINT3 和 UINT6 的操作和数据类型,以实现更高效的 LLM 权重压缩。
- 常见的 OV 标头已经过优化,从而缩短了二进制编译时间并减少了二进制大小。
AUTO 推理模式
- 在选择设备以实现快速首次推理延迟时,AUTO 会考虑模型缓存。如果模型缓存已到位,AUTO 将直接使用所选设备,而不是暂时利用 CPU 作为首次推理设备。
- 动态模型现在被加载到选定的设备,而不是不考虑设备优先级而加载到 CPU。
- 修复了在具有动态输入或输出的状态模型中使用 AUTO 时出现的异常。
CPU 设备插件
- 在英特尔客户端平台上,包括 Core Ultra(代号 Meteor Lake)和第 13 代 Core 处理器(代号 Raptor Lake),使用 FP32 精度延迟模式时的性能得到了改进。
- 在基于 AVX2 和 AVX512 的 CPU 平台上,FP16 LLM 的第二个令牌延迟和内存占用得到了显著改善,尤其是对于小批量而言。
- PagedAttention 已在 AVX2、AVX512 和 AMX 平台上进行了优化,并支持 INT8 KV 缓存,以提高在 Intel CPU 上处理 LLM 工作负载时的性能。
- 具有共享嵌入的 LLM 已经过优化,以提高包括 Gemma 在内的多个模型的性能和内存消耗。
- 升级到 TBB 2021.2.5 后,基于 ARM 的服务器的性能得到显著提升。
- 提高了 ARM CPU 上的 FP32 和 FP16 性能。
GPU 设备插件
- 所有 GPU 平台上的 LLM 第一个令牌和平均令牌延迟均得到改善,在独立 GPU 上改善最为显著。LLM 的内存使用量也减少了。
- 在 Core Ultra 平台上,Stable Diffusion FP16 性能得到改善,对于具有动态形状输入的模型,管道得到显著改进。管道的内存使用量也得到了减少。
- 优化的permute_f_y内核性能得到了提升。
NPU 设备插件
- 现在有一组新的配置选项可用。
- 采用新的2408 NPU 驱动程序,性能提升已得到解锁 。
OpenVINO Python API
- 现在支持在基本场景中编写自定义 Python 运算符(与 OpenVINO C++ API 保持一致)。这使用户能够将自己的专门操作实现到任何模型中。即将发布的版本将提供全面支持和更多高级功能。
OpenVINO C API
- 现在支持更多元素类型以使用 OpenVINO C++ API。
OpenVINO Node.js API
- OpenVINO node.js 软件包现在支持 electron.js 框架。
- 扩展和改进了 JS API 文档,以获得更完整的使用指南。
- JS API 与 OpenVINO C++ API 更好地协调,为 JS 用户提供更多高级功能。
TensorFlow 框架支持
- 现支持 3 个新操作。请 在此处查看这些新操作。
- LookupTableImport 获得了更好的支持,这是 TF Hub 中两个模型所必需的:
- mil-nce
- openimages-v4-ssd-mobilenet-v2
TensorFlow Lite 框架支持
- 现在支持客户模型所需的 GELU 操作。
PyTorch 框架支持
- 现在支持 9 种新操作。
- aten::set_item 现在支持负索引。
- 当形状为列表时自适应池的问题已修复(PR #24586)。
ONNX 支持
- 从现在开始应该使用 InputModel 接口,而不是许多已弃用的 API 和类符号。
- 已添加 ReduceMin-18 和 ReduceSumSquare-18 运算符的翻译,以满足客户模型请求。
- 当“无”被设置为默认值时,Gelu-20 操作员的行为已得到修复。
OpenVINO 模型服务器
- OpenVINO 模型服务器现在可以使用与 OpenAI 兼容的 API 来生成文本用例。
- 增加了对连续批处理和 PagedAttention 算法的支持,用于在高并发负载下快速高效地生成文本,尤其是在 Intel Xeon 处理器上。了解更多信息。
神经网络压缩框架
- nncf.compress_weights() 现在支持 GPTQ 方法,用于 LLM 的数据感知 4 位权重压缩。通过 nncf.compress_weights() 中的 gptq=True` 启用。
- 用于更精确的 4 位压缩 LLM 的比例估计算法。通过 nncf.compress_weights() 中的 scale_estimation=True` 启用。
- 在 nncf.compress_weights() 中添加了对具有 bf16 权重的模型的支持。
- nncf.quantize() 方法现在是 Quantization-Aware Training 中 PyTorch 模型量化初始化的推荐路径。有关更多详细信息,请参阅示例。
- 已添加 compressed_model.nncf.get_config() 和 nncf.torch.load_from_config() API 来保存和恢复量化的 PyTorch 模型。有关更多详细信息,请参阅示例。
- 已添加对具有自定义模块的 PyTorch 模型的 int8 量化的自动支持。现在无需在量化之前注册此类模块。
其他变更和已知问题
Jupyter Notebook
- 最新 notebook 以及 GitHub 验证状态可在 OpenVINO Notebooks 部分找到
- 以下笔记本已更新或新增:
已知的问题
组件:TBB
编号: TBB-1400/ TBB-1401
描述:
在 2024.2 中,oneTBB 2021.2.x 用于英特尔 OpenVINO Ubuntu 和 Red Hat 发行版档案,而不是系统 TBB/oneTBB。这提高了新一代英特尔® 至强® 平台的性能,但可能会增加上一代某些型号的延迟。您可以使用 -DSYSTEM_TBB=ON构建 OpenVINO ,以获得这些型号更好的延迟性能。
组件:python API
编号:CVS-141744
描述:
在提交后测试期间,我们发现与自定义操作相关的问题。修复已准备就绪,将在 2024.3 版本中提供。
– 初始问题:test_custom_op 在销毁时挂起,因为它正在等待试图获取 GIL 的线程。
– 第二个问题是 pybind11 不允许在当前范围之外使用 GIL,并且无法为析构函数释放 GIL。阻止析构函数和 GIL pybind/pybind11#1446
– 当前解决方案允许释放 InferRequest 的 GIL 以及所有由链式析构函数调用的 GIL。
组件:CPU Runtime
编号: MFDNN-11428
描述:
由于采用了新的 OneDNN 库,大多数用例的性能都有所提高,特别是具有延迟提示的 AVX2 BRGEMM 内核,可能会注意到以下回归:
a. 某些模型的延迟回归,例如 MTL Windows 延迟模式下的 unet-camvid-onnx-0001 和 mask_rcnn_resnet50_atrous_coco
b. 如果使用吞吐量提示,英特尔客户端平台上的性能会下降
我们正在调查该问题并计划在后续版本中解决。
组件:硬件配置
身份证: 无
描述:
在较新的 CPU 上可能会观察到 LLM 性能下降。为了缓解这种情况,请修改 BIOS 中的默认设置,将系统更改为 2 NUMA 节点系统:
1.进入BIOS配置菜单。
2. 选择EDKII菜单->Socket配置->Uncore配置->Uncore常规配置->SNC。
3. SNC 设置默认设置为 AUTO 。将 SNC 设置更改为 禁用, 以便在启动时为每个处理器插槽配置一个 NUMA 节点。
4. 系统重启后,使用 numatcl -H 确认 NUMA 节点设置。预计在 2 插槽系统上仅会看到节点 0 和 1,映射如下:
节点 – 0 – 1
0 – 10 – 21
1 – 21 – 10
弃用和支持
不建议使用已弃用的功能和组件。它们可用于顺利过渡到新解决方案,将来会停用。要继续使用已停用的功能,您必须恢复到支持它们的最后一个 LTS OpenVINO 版本。有关更多详细信息,请参阅 OpenVINO 旧版功能和组件 页面。
2024 年停止的组件
- Runtime 组件:
- 英特尔® 高斯与神经加速器(英特尔® GNA)。考虑将神经处理单元 (NPU) 用于低功耗系统,如英特尔® 酷睿™ Ultra 或第 14 代及更高版本。
- OpenVINO C++/C/Python 1.0 API(请参阅 2023.3 API 过渡指南 以供参考)。
- 所有 ONNX 前端遗留 API(称为 ONNX_IMPORTER_API)。
- PerfomanceMode.UNDEFINED ( OpenVINO Python API 的一部分)。
- 工具:
- 部署管理器。请参阅 安装 和 部署 指南以了解当前的分发选项。
- 准确度检查器。
- 训练后优化工具 (POT)。应使用神经网络压缩框架(NNCF)。
- 用于 NNCF 与 huggingface/transformers集成的Git 补丁。 推荐的方法是使用 huggingface/optimum-intel 在 Hugging Face 的模型之上应用 NNCF 优化。
- 支持 Apache MXNet、Caffe 和 Kaldi 模型格式。转换为 ONNX 可作为解决方案。
已弃用并将在将来删除
- 从 OpenVINO 2025 开始,OpenVINO™ 开发工具包(pip install openvino-dev)将从安装选项和分发渠道中删除。
- 模型优化器将在 OpenVINO 2025.0 中停用。请考虑改用 新的转换方法 。有关更多详细信息,请参阅 模型转换过渡指南。
- OpenVINO 属性 Affinity API 将从 OpenVINO 2025.0 开始停用。它将被 CPU 绑定配置 ( ) 取代
ov::hint::enable_cpu_pinning。 - OpenVINO 模型服务器组件:
- 将来会删除“自动形状”和“自动批量大小”(在运行时重塑模型)。建议改用 OpenVINO 的动态形状模型。
- 许多笔记本已被弃用。如需了解可用笔记本的最新列表,请参阅 OpenVINO™ 笔记本索引 (openvinotoolkit.github.io)。
OpenVINO 2024.2 Docker 镜像
为了方便快速上手 OpenVINO 2024.2 版本,我还编译了两个 OpenVINO 2024.2 docker 镜像,分别是 dev 镜像和 runtime 镜像,可以从如下的地址下载:
- dev 镜像(大小约 4.2GB,包含开发环境,Jupyter Notebook,适合开发)
- runtime 镜像(大小约 640MB,仅包含必须的 runtime 环境,适合产品部署)
先将上述的 docker 镜像 .tar 文件保存到本地,然后执行如下的命令加载 docker 镜像(以 dev 镜像为例):
sudo docker load -i ubuntu_2204_openvino_dev_2024.2.tar
加载成功后运行如下命令查看:
sudo docker image list
执行如下的命令运行 OpenVINO 容器:
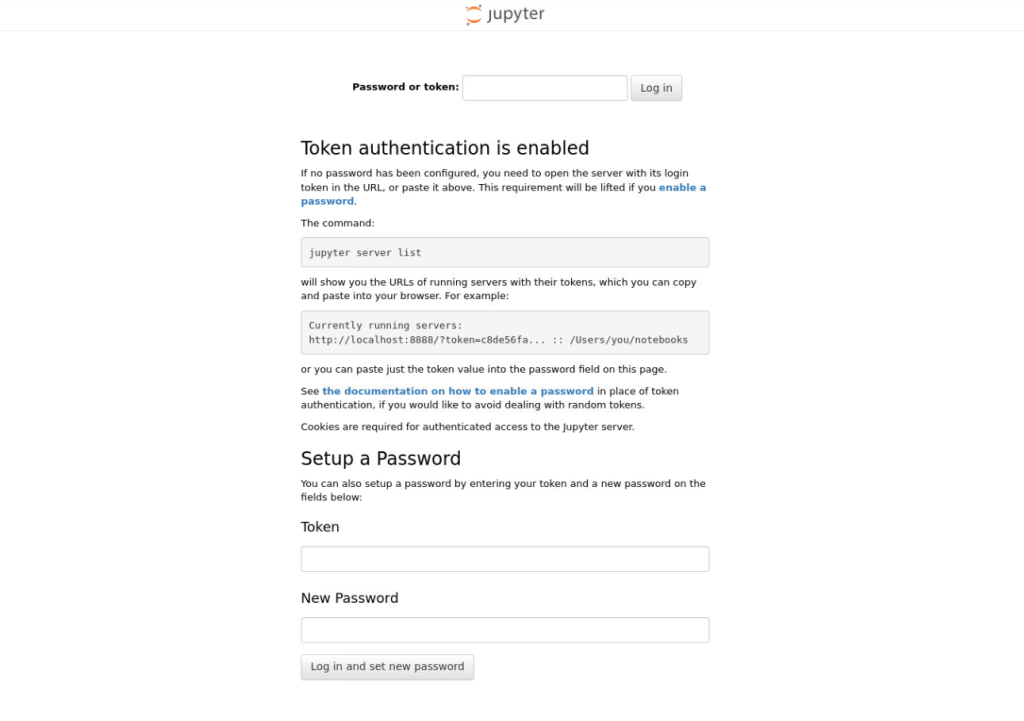
docker run -it --detach --name ubuntu_2204_openvino_dev_2024_2 --device /dev/dri:/dev/dri --device-cgroup-rule='c 189:* rmw' -p 8888:8888 -v /dev/bus/usb:/dev/bus/usb -v /path_on_your_host_machine:/home/openvino ubuntu_2204_openvino_dev:2024.2容器运行成功后,访问 http://your_ip_address:8888 就可以正常看到如下的 Jupyter Notebook 登录界面,此时就可以开始使用 notebook 来体验 OpenVINO 2024.2 版本了。
英特尔官方的 notebooks 可以从这里下载:https://openvinotoolkit.github.io/openvino_notebooks/。