

有没有想过在树莓派(Raspberry Pi)设备上运行自己的大型语言模型 (LLM) 或视觉语言模型 (VLM)?你可能想过,但一想到要从头开始设置,必须管理环境,下载正确的模型权重,以及对设备是否能处理该模型的挥之不去的疑虑,你可能会犹豫不决。
目前,边缘的 LLM 似乎还遥不可及。但随着时间的推移,这种特定的利基用例应该会逐渐成熟,我们肯定会看到一些很酷的边缘解决方案被部署,并在边缘设备上运行全本地生成 AI 解决方案。
树莓派(Raspberry Pi)介绍
Raspberry Pi 是一系列低成本、单板计算机,由英国的 Raspberry Pi 基金会开发,目的是促进计算机教育。自2012年首次发布以来,Raspberry Pi 已被广泛应用于教育、DIY项目和各种专业领域。Raspberry Pi 系列的设备体积小、功能强,且具有极高的性价比。

主要特点
- 多种型号:
- 从早期的 Raspberry Pi Model A 和 Model B,到后来的 Raspberry Pi 2、Raspberry Pi 3 以及最新的 Raspberry Pi 4,每一代产品都在性能和功能上有显著提升。
- 通用设计:
- 所有型号都配有 GPIO 接口,用于连接外设和传感器,支持各种 DIY 和专业应用。
- 通用的形状和布局,使得硬件配件和外壳可以互换使用。
- 丰富的生态系统:
- 大量的开源软件和社区支持,包括各种操作系统和开发工具。
- 丰富的外设和配件,从相机模块、触摸屏到各种传感器和扩展板。
树莓派 5 介绍
树莓派 5 (Raspberry Pi 5) 是最新发布的树莓派系列单板计算机,具有显著的性能提升和新的功能特性。与前代产品相比,树莓派 5 在处理能力、图形性能和接口扩展性方面都有明显改善。
主要规格
- 处理器:
- Broadcom BCM2712,四核 Arm Cortex-A76 处理器,主频为 2.4GHz。
- 每个核心拥有 512KB L2 缓存,共享 2MB L3 缓存。
- 图形处理:
- VideoCore VII GPU,支持 OpenGL ES 3.1 和 Vulkan 1.2。
- 支持双 4K@60Hz HDMI 显示输出,并支持 HDR。
- 内存:
- 提供 4GB 和 8GB LPDDR4X-4267 SDRAM 选项。
- 网络连接:
- 双频 802.11ac Wi-Fi。
- 蓝牙 5.0 和 Bluetooth Low Energy (BLE)。
- 千兆以太网,并支持 PoE+(需要额外的 PoE+ HAT)。
- 存储:
- microSD 卡插槽,支持高速 SDR104 模式。
- 提供 PCIe 2.0 x1 接口,可用于快速外设(需要额外的 M.2 HAT 或其他适配器)。
- 接口:
- 2 个 USB 3.0 端口,支持 5Gbps 数据传输。
- 2 个 USB 2.0 端口。
- 2 个 4-lane MIPI 摄像头/显示器接口。
- 电源和散热:
- 通过 USB-C 供电,推荐使用 5V/5A 电源适配器,支持电源传递功能。
- 内置 RTC(实时时钟),需要外部电池供电。
- 需要主动散热,官方推荐使用带风扇的专用外壳 (raspberrypi) (datasheets.raspberrypi) (techcrunch)。
那么,我们如何在 Raspberry Pi 上实现本地运行 LLM 和 VLM 呢?使用 Ollama!
什么是 Ollama?
Ollama 是在个人计算机上运行本地 LLM 的最佳解决方案之一,无需从头开始进行设置。只需几个命令,一切都可以顺利完成,并且在多种设备和型号上都能很好地运行。它甚至公开了一个用于模型推理的 REST API,因此您可以让它在 Raspberry Pi 上运行,并在需要时从其他应用程序和设备调用它。
还有Ollama Web UI,这是一款漂亮的 AI UI/UX,可与 Ollama 无缝运行,适合那些对命令行界面感到担忧的人。如果你愿意的话,它基本上是一个本地 ChatGPT 界面。
总之,这两款开源软件提供了我认为目前最好的本地托管 LLM 体验。
Ollama 和 Ollama Web UI 都支持 LLaVA 等 VLM,这为这种边缘生成 AI 用例打开了更多的大门。
技术要求
您只需要以下内容:
- Raspberry Pi 5(或 4,适用于速度较慢的设置)— 选择 8GB RAM 版本以适合 7B 型号。
- SD 卡 — 至少 16GB,容量越大,可以容纳的模型越多。已加载适当的操作系统,例如 Raspbian Bookworm 或 Ubuntu
- 互联网连接
正如我之前提到的,在 Raspberry Pi 上运行 Ollama 已经接近硬件频谱的极限。从本质上讲,任何比 Raspberry Pi 更强大的设备,只要它运行 Linux 发行版并具有类似的内存容量,理论上都应该能够运行 Ollama 和本文中讨论的模型。
1.安装Ollama
要在 Raspberry Pi 上安装 Ollama,我们将避免使用 Docker 以节省资源。
在终端中运行:
curl https://ollama.ai/install.sh | sh运行上述命令后,您应该会看到类似下图的内容。
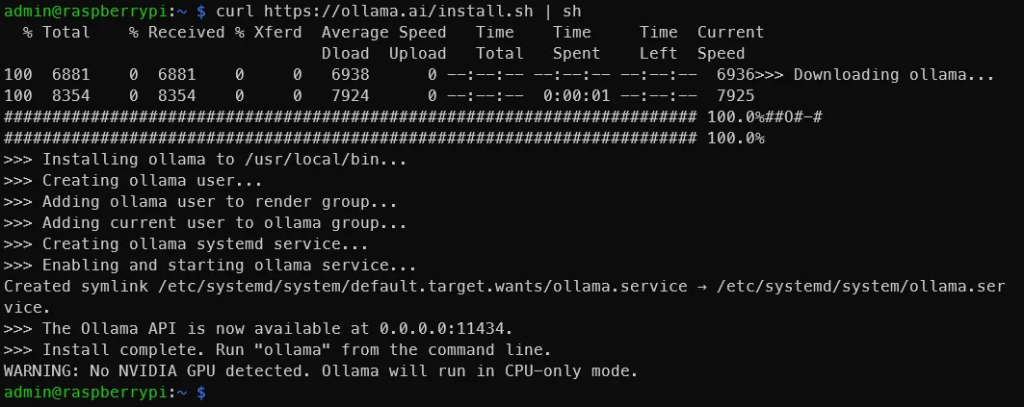
就像输出中说的那样,转到 0.0.0.0:11434 以验证 Ollama 是否正在运行。由于我们使用的是 Raspberry Pi,因此看到“警告:未检测到 NVIDIA GPU。Ollama 将以仅 CPU 模式运行。”
如有任何问题或更新,请参阅Ollama GitHub repository。
2. 通过命令行运行 LLM
查看官方 Ollama 模型库,了解可使用 Ollama 运行的模型列表。在 8GB Raspberry Pi 上,大于 7B 的模型无法容纳。我们使用 Phi-2,这是微软的 2.7B LLM,现在已获得 MIT 许可。
我们将使用默认的 Phi-2 模型,但您也可以随意使用此处的任何其他标签。查看Phi-2 模型页面,了解如何与其交互。
在终端中运行如下命令:
ollama run phi一旦您看到类似于以下输出的内容,您就已经在 Raspberry Pi 上运行了 LLM!就这么简单。
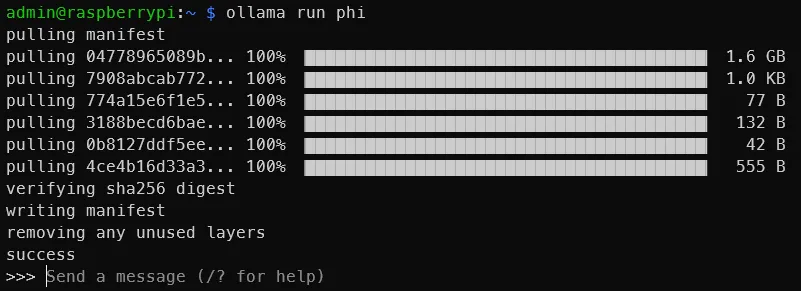

您可以尝试其他模型,如 Mistral、Llama-2 等,只需确保 SD 卡上有足够的空间容纳模型重量。
当然,模型越大,输出速度就越慢。在 Phi-2 2.7B 上,我每秒可以得到大约 4 个 token。但是使用 Mistral 7B,生成速度会下降到每秒大约 2 个 token。一个 token 大致相当于一个单词。
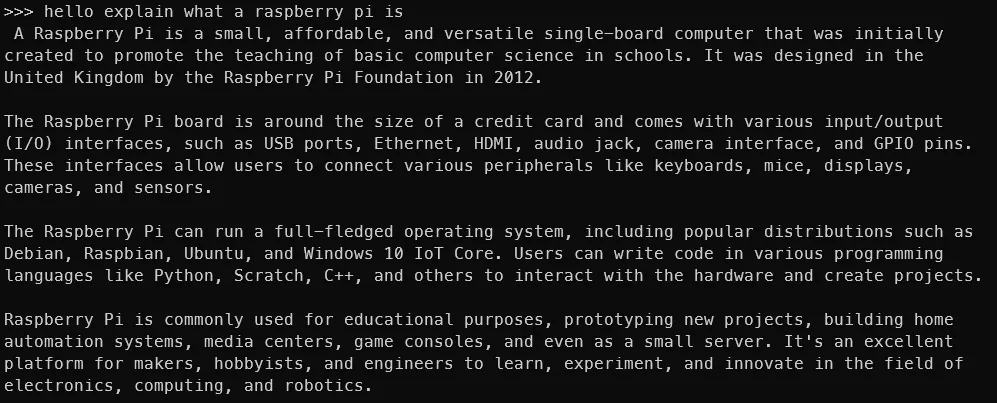
现在,我们已经在 Raspberry Pi 上运行了 LLM,但还没有完成。终端并不适合所有人。让我们也运行 Ollama Web UI!
3.安装并运行Ollama Web UI
我们将按照官方 Ollama Web UI GitHub repository上的说明进行安装,无需 Docker。它建议 Node.js 至少为 >= 20.10,所以我们将遵循这一点。它还建议 Python 至少为 3.11,但 Raspbian OS 已经为我们安装了它。
我们必须先安装 Node.js。在终端中,运行:
curl -fsSL https://deb.nodesource.com/setup_20.x | sudo -E bash - &&\
sudo apt-get install -y nodejs如果需要,请将 20.x 更改为更合适的版本。
然后运行下面的代码块。
git clone https://github.com/ollama-webui/ollama-webui.git
cd ollama-webui/
# 复制所需的 .env 文件
cp -RPp example.env . env
# 使用 Node 构建前端
npm i
npm run build
# 使用后端为前端提供服务
cd ./backend
pip install -r requirements.txt --break-system-packages
sh start.sh这是对 GitHub 上提供的内容的轻微修改。请注意,为了简单起见,我们没有遵循使用虚拟环境等最佳实践,而是使用了 —break-system-packages 标志。如果遇到未找到 uvicorn 之类的错误,请重新启动终端会话。
如果一切顺利,您应该能够通过Raspberry Pi 上的http://0.0.0.0:8080访问端口 8080 上的 Ollama Web UI ,或者如果您通过同一网络上的另一台设备访问,则可以通过 http://<Raspberry Pi 的本地地址>:8080/ 访问。
创建帐户并登录后,您应该会看到类似下图的内容。
如果您之前已下载一些模型权重,您应该会在下拉菜单中看到它们,如下所示。如果没有,您可以前往设置下载模型。

整个界面非常干净直观,所以我就不多解释了。这确实是一个非常出色的开源项目。

4. 通过 Ollama Web UI 运行 VLM
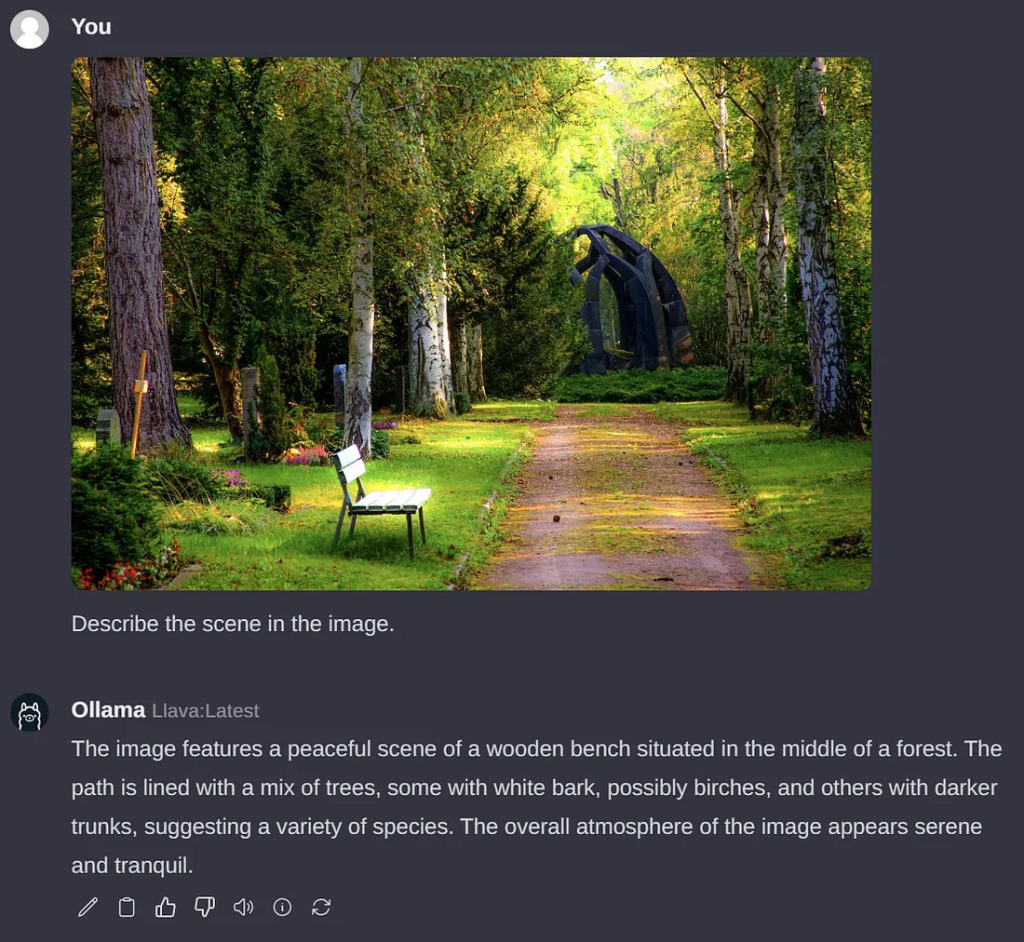
正如我在本文开头提到的,我们也可以运行 VLM。让我们运行 LLaVA,这是一种流行的开源 VLM,恰好也得到了 Ollama 的支持。为此,请通过界面拉取“llava”来下载权重。
不幸的是,与 LLM 不同,安装程序需要相当长的时间才能解释 Raspberry Pi 上的图像。下面的示例大约需要 6 分钟才能处理完毕。大部分时间可能是因为图像方面尚未得到适当优化,但这在未来肯定会改变。令牌生成速度约为 2 个令牌/秒。
总结
至此,我们基本上完成了本文的目标。总结一下,我们已成功使用 Ollama 和 Ollama Web UI 在 Raspberry Pi 上运行 LLM 和 VLM,如 Phi-2、Mistral 和 LLaVA。
我可以想象在 Raspberry Pi(或其他小型边缘设备)上运行本地托管的 LLM 的相当多用例,特别是如果我们要使用 Phi-2 大小的模型,那么 4 个令牌/秒对于某些用例来说似乎是一个可以接受的流式传输速度。
“小型” LLM 和 VLM 领域(由于其“大型”名称而得名,这有点自相矛盾)是一个活跃的研究领域,最近发布了不少模型。希望这种新兴趋势能够持续下去,并继续发布更高效、更紧凑的模型!


