在快速发展的人工智能领域,大型语言模型已成为该领域最新突破的主角。
文本生成已成为一项突破性的功能,改变了机器理解和生成类似人类的文本的方式。正是由于这种流行,才推出了多种工具来简化和促进 LLM 的工作流程。
大型语言模型(LLM)迅速普及,几乎每周都会出现新的模型,这引发了用于容纳这项技术的托管选项的同步增长。在可用于此目的的众多工具中,Hugging Face 的文本生成推理 (Text Generation Inference,TGI) 尤其值得一提,因为它允许我们在本地机器上将 LLM 作为服务运行。
简单地说,它允许我们有一个端点来调用我们的模型。
本指南将探讨 Huggingface TGI 为何会改变游戏规则,以及如何利用它来创建复杂的 AI 模型,该模型能够生成与人类生成的文本越来越难以区分的文本。
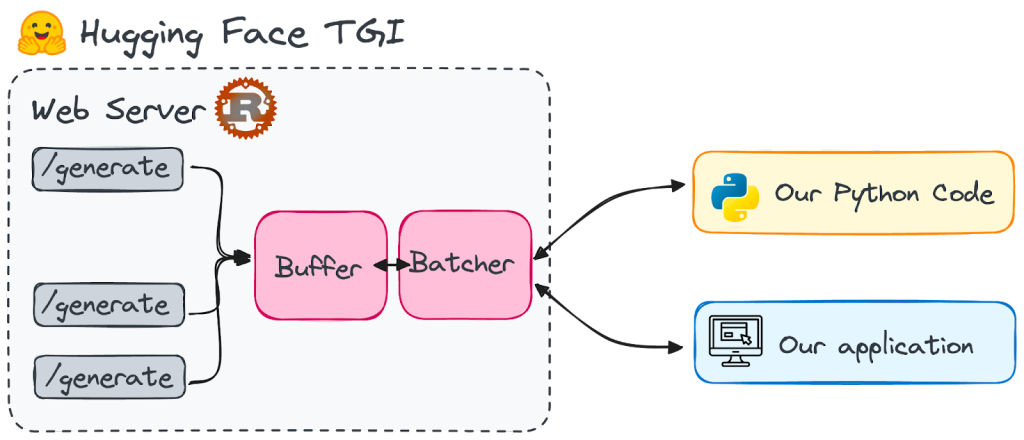
什么是Huggingface Text Generation Inference?
Huggingface Text Generation Inference(也称为 TGI)是一个用 Rust 和 Python 编写的框架,用于部署和提供大型语言模型。它是一个可用于部署和提供 LLM 的生产工具包。
Huggingface 根据 HFOILv1.0 许可证开发和分发它,允许商业使用,前提是它作为所提供产品或服务中的辅助工具,而不是主要焦点。它解决的主要挑战是:
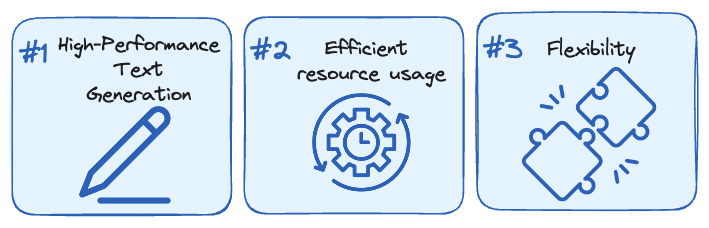
- 高性能文本生成。TGI使用张量并行(一种用于在多个 GPU 中拟合大型模型的技术)和动态批处理(在服务器内部动态批处理提示)等技术来优化流行开源 LLM 的性能,包括 StarCoder、BLOOM、GPT-NeoX、Llama 和T5等模型。
- 高效的资源使用。连续批处理、优化代码和张量并行等功能使 TGI 能够同时处理多个请求,同时最大限度地减少资源使用。
- 灵活性。TGI支持各种安全功能,如水印、logit 扭曲(通过向特定标记注入偏差值来修改特定标记的 logit)以进行偏差控制,以及停止序列以确保负责任且受控的 LLM 使用。
Huggingface 优化了一些 LLM 的架构,以便它们在 TGI 上运行得更快。这包括LLaMA、Falcon7B 和 Mistral 等流行模型。完整列表可在其文档中找到。
为什么要使用 Huggingface TGI?
Huggingface 已成为开发具有自然语言能力的 AI 的首选之地。它是所有开源重量级模型聚集的中心,使其成为 NLP 创新的强大力量。到目前为止,这些模型中的大多数都过于繁重,无法直接在本地使用;它们始终依赖于基于云的服务。
然而,考虑到 QLoRa 和 GPTQ 等量化技巧的最新进展,一些 LLM 已经可以在我们的日常设备(如本地计算机)上进行管理。
Hugging Face TGI 专门为我们提供本地机器上的 LLM 服务而设计。这背后的主要原因是启动 LLM 的麻烦。
为了避免停机,更明智的做法是让模型在后台准备就绪,以便快速响应。否则,每次你调用它时,你都会陷入漫长的等待循环中。想象一下,有一个端点,里面有一组最好的语言模型,随时听候你的召唤,随时准备按照你的意愿编织单词。
TGI 最吸引我的地方在于它的简洁方法。目前,TGI 已准备好与一系列精简的模型架构配合使用,因此可以轻而易举地快速部署它们。
这并非只是说说而已;TGI 已经成为多个正在实施的项目背后的推动力。以下是一些示例:
- Hugging Chat,一个开放访问模型的开源界面。
- OpenAssistant,一个为培训法学硕士而开展的开源社区活动。
- nat.dev,一个探索和比较 LLM 的游乐场。
然而,还有一个重大问题。TGI 尚不兼容基于 ARM 的 GPU Mac,包括 M1 系列及更高型号。
设置 Huggingface TGI
首先,我们需要设置我们的 Huggingface TGI endpoint。
要在本地安装和启动 Hugging Face TGI,首先需要安装 Rust,然后创建一个至少具有 Python 3.9 的 Python 虚拟环境,例如使用 conda:
#Installing Rust
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
#Creating a python virtual environment
conda create -n text-generation-inference python=3.9
conda activate text-generation-inference此外,还需要安装 Protoc。Hugging Face 建议使用版本 21.12 以获得最佳兼容性。请注意,您需要 sudo 权限才能继续此安装。
PROTOC_ZIP=protoc-21.12-linux-x86_64.zip
curl -OL https://github.com/protocolbuffers/protobuf/releases/download/v21.12/$PROTOC_ZIP
sudo unzip -o $PROTOC_ZIP -d /usr/local bin/protoc
sudo unzip -o $PROTOC_ZIP -d /usr/local 'include/*'
rm -f $PROTOC_ZIP我们将从头开始安装它,本地安装的过程相对复杂。如果您在此过程中遇到问题,可以跳过第一部分并直接运行 Docker 映像,相对会更加简单。
满足所有先决条件后,我们就可以设置 TGI 了。首先克隆 GitHub 存储库:
git clone https://github.com/huggingface/text-generation-inference.git然后,切换到本地计算机上的TGI位置并使用以下命令进行安装:
cd text-generation-inference/
BUILD_EXTENSIONS=False make install现在让我们看看如何使用 TGI。我将使用 Falcon-7B 模型,该模型在 Apache 2.0 许可下可用。
1. 不使用 Docker 启动模型
安装创建了一个新命令“text-generation-launcher”,它将启动 TGI 服务器。要激活 Falcon-7B 模型的端点,我们只需执行以下命令:
text-generation-launcher --model-id tiiuae/falcon-7b-instruct --num-shard 1 --port 8080 --quantize bitsandbytes其中每个输入参数为:
- model-id:指的是 Hugging Face Hub 上列出的模型的具体名称。在我们的例子中,Falcon-7B 是 tiiuae/falcon-7b-instruct
- num-shard:调整此值以匹配您希望使用的 GPU 数量。默认情况下,该值为 1。
- port:指定您希望服务器监控请求的端口。默认情况下,该端口为 8080。
- 量化:对于使用 VRAM 低于 24 GB 的 GPU 的用户,模型量化是必要的,以防止内存过载。在前面的命令中,我选择“bitsandbytes”进行立即量化。还有另一个选项 GPTQ(“gptq”),尽管我不太熟悉它的工作原理。
2. 使用 Docker 启动模型(更直接)
确保你的电脑上安装了 Docker 并且它正在运行。如果你没有使用过 Docker,你可以按照这个访问 https://www.docker.com 来学习最基本的概念。
请记住,TGI 与 MX 处理器 Mac 型号不兼容。您可以在相应的TGI 软件包 GitHub 存储库中查看所有可用的 TGI 映像。如果您的设备兼容,Docker 应该会为您找到相应的映像。
这些参数与文本生成启动器使用的参数非常相似。如果您只使用单个 GPU,请将“all”替换为“0”。
volume=$PWD/data
sudo docker run --gpus all --shm-size 1g -p 8080:80 -v $volume:/data ghcr.io/huggingface/text-generation-inference:0.9 --model-id tiiuae/falcon-7b-instruct --num-shard 1 --quantize bitsandbytes确保 Docker 映像在您计划使用服务器期间保持活动状态。
在应用程序中使用 TGI
您有多种方式可以将文本生成推理 (TGI) 服务器集成到您的应用程序中。一旦它启动并运行,您可以通过向 /generate 端点发出 POST 请求来与其交互以检索结果。

如果您希望 TGI 连续传输令牌,请改用端点,我们将在下一节中看到。您可以使用您选择的工具(包括 curl、Python 或 TypeScript)发出这些请求。要使用 Python 脚本查询 TGI 提供的模型,您必须安装以下文本生成库。
pip install text-generation启动 TGI 服务器后,使用为模型提供服务的端点的 URL 实例化 InferenceClient()。然后,您可以调用 text_generation() 通过 Python 访问端点。
from text_generation import Client
client = Client("http://127.0.0.1:8080")
client.text_generation(prompt="Your prompt here!")要使用 InferenceClient 启用流式传输,您只需设置 stream=True。这将允许您在服务器上生成令牌时实时接收它们。以下是您可以使用流式传输的方法:
for token in client.text_generation("Your prompt here!", max_new_tokens=12, stream=True):
print(token)通过 TGI 提示模型
我们将使用在本地部署的模型,在此例中是 Falcon-7B。通过使用 TGI,我们创建了一个实时端点,使我们能够从我们选择的 LLM 检索响应。
因此,当使用 Python 时,我们可以通过本地设备上托管的客户端直接向 LLM 发送提示,可通过端口 8080 访问。因此相应的 Python 脚本看起来像这样:
from text_generation import Client
client = Client("http://127.0.0.1:8080")
print(client.generate("Translate the following sentence into spanish: 'What does Large Language Model mean?'", max_new_tokens=500).generated_text)我们将从模型中获得响应,而无需将其安装在我们的环境中。 我们可以直接使用 CURL 查询 LLM,而不是使用 Python,如以下示例所示:
curl 127.0.0.1:8080/generate \
-X POST \
-d '{"inputs":"Code in Javascript a function to remove all spaces in a string and then print the string twice.","parameters":{"max_new_tokens":500}}' \
-H 'Content-Type: application/json'