

大型语言模型 (LLM) 彻底改变了我们从大量文本数据中提取信息和观点的方式。在财务分析领域,LLM 应用程序旨在帮助分析师回答有关公司业绩、收益报告和市场趋势的复杂问题。其中一个应用涉及使用检索增强生成 (RAG) 管道来促进从财务报表和其他来源提取信息。
设想这样一个场景:一位财务分析师想要了解某公司第二季度财报电话会议的关键要点,特别是该公司正在构建的技术护城河。这类问题超出了简单的查找范围,需要更复杂的方法。这就是 LLM 代理的概念发挥作用的地方。
什么是代理?
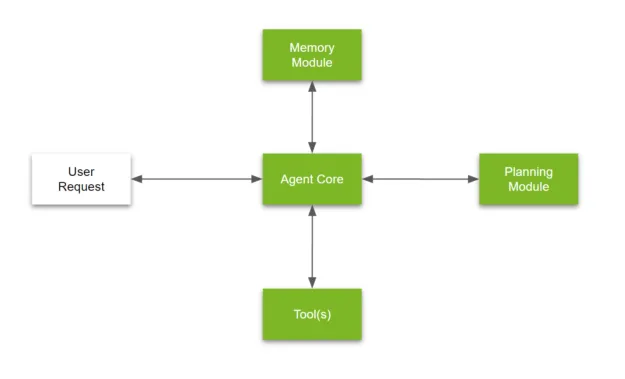
根据 Llama-Index 的说法,“代理”是一种自动推理和决策引擎。它接收用户输入/查询,并可以做出内部决策来执行该查询以返回正确的结果。关键代理组件包括但不限于:
- 将复杂问题分解为较小的问题
- 选择要使用的外部工具 + 提出调用该工具的参数
- 规划一系列任务
- 将之前完成的任务存储在记忆模块中
LLM 代理是一个结合了规划、定制焦点、内存利用率和使用不同工具来回答复杂问题的系统。
让我们分析一下如何开发 LLM 代理来回答上述问题:
- 规划( Planning ): LLM 代理首先需要了解问题的性质,并制定计划来提取相关信息。这包括确定“第二季度收益电话会议”和“技术护城河”等关键词,并确定收集这些信息的最佳来源。
- 量身定制的焦点( Tailored Focus): LLM 代理随后将注意力集中在与技术护城河相关的问题的具体方面。这涉及过滤掉不相关的信息并专注于与分析师的询问最相关的细节。
- 记忆( Memory ): LLM Agent 利用其记忆来回忆过去的收益电话会议、公司报告和其他来源的相关信息。这有助于提供上下文和背景信息来支持其分析。
- 使用不同的工具: LLM 代理利用一系列工具和技术来提取和分析信息。这可能包括自然语言处理 (NLP) 算法、情绪分析和主题建模,以深入了解收益电话会议。
- 分解复杂问题:最后,LLM 代理将复杂问题分解为更简单的子部分,从而更容易提取相关信息并提供连贯的答案。
工具调用
在标准 RAG 中,LLM 主要仅用于信息合成。
另一方面,工具调用在 RAG 管道之上添加了一层查询理解,使用户能够提出复杂的查询并返回更精确的结果。这允许 LLM 弄清楚如何使用 vectordb,而不仅仅是使用它的输出。
工具调用使 LLM 能够通过动态接口与外部环境进行交互,其中工具调用不仅有助于选择合适的工具,还可以推断执行所需的参数。因此,与标准 RAG 相比,可以更好地理解问题并产生更好的响应。
代理推理循环
如果用户问了一个由多个步骤组成的复杂问题,或者一个需要澄清的模糊问题,该怎么办?这时,代理推理循环就派上用场了。代理不是在单次设置中调用它,而是能够通过多个步骤对工具进行推理。
代理架构
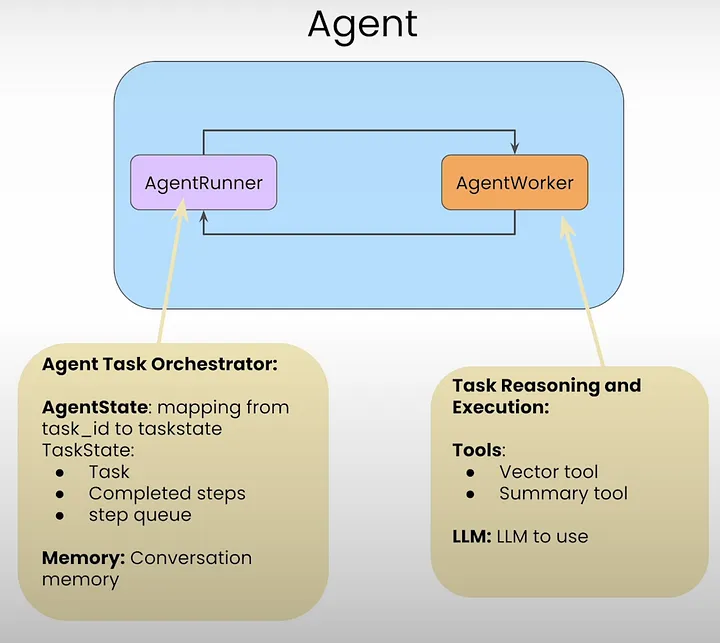
在 LlamaIndex 中,代理由两个组件组成:
- 代理运行器( AgentRunner )
- 代理工作者( AgentWorkers )
AgentRunner对象与AgentWorkers接口。
AgentRunners是存储以下内容的编排器:
- 状态
- 会话记忆
- 创建任务
- 维护任务
- 运行每个任务的步骤
- 呈现面向用户的高级用户界面
AgentWorkers负责:
- 选择和使用工具
- 选择 LLM 来使用这些工具。
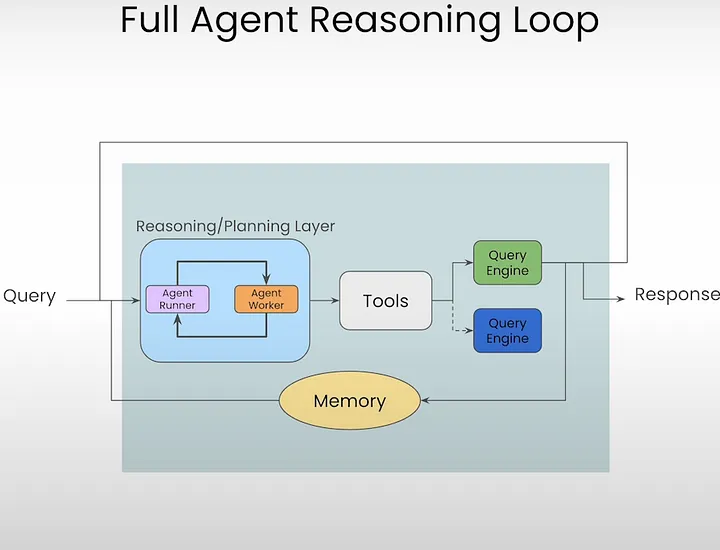
调用代理查询允许一次性查询代理,但不保留状态。这就是内存方面发挥作用的地方,用于维护对话历史记录。在这里,代理将聊天历史记录保存到对话内存缓冲区中。默认情况下,内存缓冲区是一个平面项目列表,它是一个滚动缓冲区,取决于 LLM 的上下文窗口大小。因此,当代理决定使用工具时,它不仅使用当前聊天,还使用之前的对话历史记录来执行下一组操作。
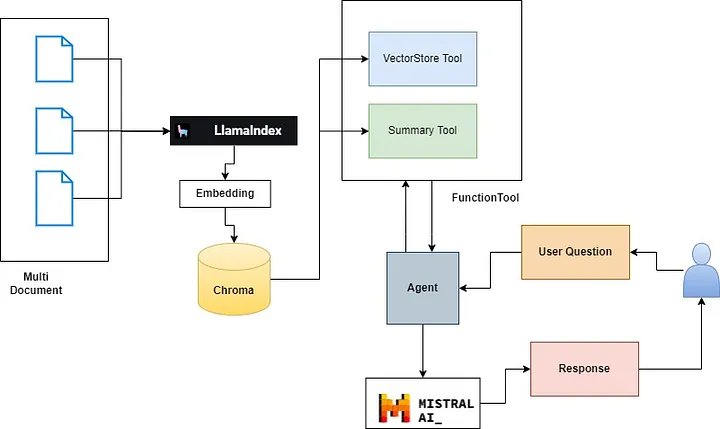
在这里,我们将构建一个多文档代理来处理多个文档。在这里,我们在 3 个文档上实施了 Agentic RAG,同样可以扩展到更多文档。
使用的技术堆栈
- Llama-Index:LlamaIndex 是用于情境增强 LLM 应用程序的数据框架。
- Mistral API:开发人员可以通过其 API 与 Mistral 进行交互,这与 OpenAI 的 API 系统的体验类似。
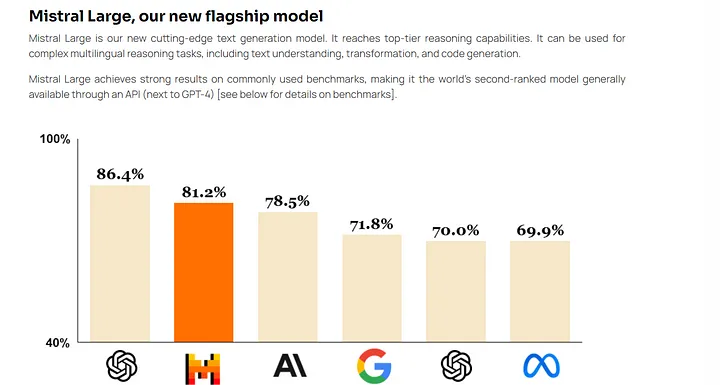
Mistral Large 具有新的功能和优势:
- 它能流利地说英语、法语、西班牙语、德语和意大利语,对语法和文化背景有细致的理解。
- 其 32K 标记上下文窗口允许从大型文档中精确调用信息。
- 其精确的指令遵循使开发人员能够设计他们的审核政策——我们用它来设置 le Chat 的系统级审核。
- 它本身具有函数调用功能。
代码实现
先创建文件 requirements.txt ,包含如下的内容,用于安装所需的依赖项。
llama-index
llama-index-llms-huggingface
llama-index-embeddings-fastembed
fastembed
Unstructured[md]
chromadb
llama-index-vector-stores-chroma
llama-index-llms-groq
einops
accelerate
sentence-transformers
llama-index-llms-mistralai
llama-index-llms-openai运行如下命令来安装依赖项。
pip install -r requirements.txt下载待处理文件。
mkdir data
wget "https://arxiv.org/pdf/1810.04805.pdf" -O ./data/BERT_arxiv.pdf
wget "https://arxiv.org/pdf/2005.11401" -O ./data/RAG_arxiv.pdf
wget "https://arxiv.org/pdf/2310.11511" -O ./data/self_rag_arxiv.pdf
wget "https://arxiv.org/pdf/2401.15884" -O ./data/crag_arxiv.pdf导入所需依赖项。
from llama_index.core import SimpleDirectoryReader,VectorStoreIndex,SummaryIndex
from llama_index.vector_stores.chroma import ChromaVectorStore
from llama_index.core import StorageContext
from llama_index.core.node_parser import SentenceSplitter
from llama_index.core.tools import FunctionTool,QueryEngineTool
from llama_index.core.vector_stores import MetadataFilters,FilterCondition
from typing import List,Optionalimport nest_asyncio
nest_asyncio.apply()读取文档内容:
documents = SimpleDirectoryReader(input_files = ['./data/self_rag_arxiv.pdf']).load_data()
print(len(documents))
print(f"Document Metadata: {documents[0].metadata}")将文档拆分成 chunks / nodes:
splitter = SentenceSplitter(chunk_size=1024,chunk_overlap=100)
nodes = splitter.get_nodes_from_documents(documents)
print(f"Length of nodes : {len(nodes)}")
print(f"get the content for node 0 :{nodes[0].get_content(metadata_mode='all')}")
###########################RESPONSE ################################
Length of nodes : 43
get the content for node 0 :page_label: 1
file_name: self_rag_arxiv.pdf
file_path: data/self_rag_arxiv.pdf
file_type: application/pdf
file_size: 1405127
creation_date: 2024-05-11
last_modified_date: 2023-10-19
Preprint.
SELF-RAG: LEARNING TO RETRIEVE , GENERATE ,AND
CRITIQUE THROUGH SELF-REFLECTION
Akari Asai†, Zeqiu Wu†, Yizhong Wang†§, Avirup Sil‡, Hannaneh Hajishirzi†§
†University of Washington§Allen Institute for AI‡IBM Research AI
{akari,zeqiuwu,yizhongw,hannaneh }@cs.washington.edu ,avi@us.ibm.com
ABSTRACT
Despite their remarkable capabilities, large language models (LLMs) often produce
responses containing factual inaccuracies due to their sole reliance on the paramet-
ric knowledge they encapsulate. Retrieval-Augmented Generation (RAG), an ad
hoc approach that augments LMs with retrieval of relevant knowledge, decreases
such issues. However, indiscriminately retrieving and incorporating a fixed number
of retrieved passages, regardless of whether retrieval is necessary, or passages are
relevant, diminishes LM versatility or can lead to unhelpful response generation.
We introduce a new framework called Self-Reflective Retrieval-Augmented Gen-
eration ( SELF-RAG)that enhances an LM’s quality and factuality through retrieval
and self-reflection. Our framework trains a single arbitrary LM that adaptively
retrieves passages on-demand, and generates and reflects on retrieved passages
and its own generations using special tokens, called reflection tokens. Generating
reflection tokens makes the LM controllable during the inference phase, enabling it
to tailor its behavior to diverse task requirements. Experiments show that SELF-
RAG(7B and 13B parameters) significantly outperforms state-of-the-art LLMs
and retrieval-augmented models on a diverse set of tasks. Specifically, SELF-RAG
outperforms ChatGPT and retrieval-augmented Llama2-chat on Open-domain QA,
reasoning and fact verification tasks, and it shows significant gains in improving
factuality and citation accuracy for long-form generations relative to these models.1
1 I NTRODUCTION
State-of-the-art LLMs continue to struggle with factual errors (Mallen et al., 2023; Min et al., 2023)
despite their increased model and data scale (Ouyang et al., 2022). Retrieval-Augmented Generation
(RAG) methods (Figure 1 left; Lewis et al. 2020; Guu et al. 2020) augment the input of LLMs
with relevant retrieved passages, reducing factual errors in knowledge-intensive tasks (Ram et al.,
2023; Asai et al., 2023a). However, these methods may hinder the versatility of LLMs or introduce
unnecessary or off-topic passages that lead to low-quality generations (Shi et al., 2023) since they
retrieve passages indiscriminately regardless of whether the factual grounding is helpful. Moreover,
the output is not guaranteed to be consistent with retrieved relevant passages (Gao et al., 2023) since
the models are not explicitly trained to leverage and follow facts from provided passages. This
work introduces Self-Reflective Retrieval-augmented Generation ( SELF-RAG)to improve an
LLM’s generation quality, including its factual accuracy without hurting its versatility, via on-demand
retrieval and self-reflection. We train an arbitrary LM in an end-to-end manner to learn to reflect on
its own generation process given a task input by generating both task output and intermittent special
tokens (i.e., reflection tokens ). Reflection tokens are categorized into retrieval andcritique tokens to
indicate the need for retrieval and its generation quality respectively (Figure 1 right). In particular,
given an input prompt and preceding generations, SELF-RAGfirst determines if augmenting the
continued generation with retrieved passages would be helpful. If so, it outputs a retrieval token that
calls a retriever model on demand (Step 1). Subsequently, SELF-RAGconcurrently processes multiple
retrieved passages, evaluating their relevance and then generating corresponding task outputs (Step
2). It then generates critique tokens to criticize its own output and choose best one (Step 3) in terms
of factuality and overall quality. This process differs from conventional RAG (Figure 1 left), which
1Our code and trained models are available at https://selfrag.github.io/ .
1arXiv:2310.11511v1 [cs.CL] 17 Oct 2023实例化 vectorstore :
import chromadb
db = chromadb.PersistentClient(path="./chroma_db_mistral")
chroma_collection = db.get_or_create_collection("multidocument-agent")
vector_store = ChromaVectorStore(chroma_collection=chroma_collection)
storage_context = StorageContext.from_defaults(vector_store=vector_store)实例化 embedding 模型:
from llama_index.embeddings.fastembed import FastEmbedEmbedding
from llama_index.core import Settings
#
embed_model = FastEmbedEmbedding(model_name="BAAI/bge-small-en-v1.5")
#
Settings.embed_model = embed_model
#
Settings.chunk_size = 1024
#实例化 LLM :
from llama_index.llms.mistralai import MistralAI
os.environ["MISTRAL_API_KEY"] = userdata.get("MISTRAL_API_KEY")
llm = MistralAI(model="mistral-large-latest")
实例化特定文档的向量查询工具和摘要工具
LlamaIndex 数据代理处理自然语言输入以执行操作而不是生成响应。创建有效数据代理的关键在于抽象工具。但在这种情况下,工具究竟是什么意思?将工具视为为代理交互而设计的 API 接口,而不是人机界面。
核心概念:
- 工具:本质上,工具包括通用接口和基本元数据,例如名称、描述和功能模式。
- 工具规范:深入研究 API 细节,提供可转化为各种工具的全面服务 API 规范。
有多种类型的工具可用:
- FunctionTool:将任何用户定义的函数转换为工具,并能够推断该函数的模式。
- QueryEngineTool:围绕现有查询引擎。由于我们的代理抽象源自 BaseQueryEngine,因此此工具也可以容纳代理。
#instantiate Vectorstore
name = "BERT_arxiv"
vector_index = VectorStoreIndex(nodes,storage_context=storage_context)
vector_index.storage_context.vector_store.persist(persist_path="/content/chroma_db")
#
# Define Vectorstore Autoretrieval tool
def vector_query(query:str,page_numbers:Optional[List[str]]=None)->str:
'''
perform vector search over index on
query(str): query string needs to be embedded
page_numbers(List[str]): list of page numbers to be retrieved,
leave blank if we want to perform a vector search over all pages
'''
page_numbers = page_numbers or []
metadata_dict = [{"key":'page_label',"value":p} for p in page_numbers]
#
query_engine = vector_index.as_query_engine(similarity_top_k =2,
filters = MetadataFilters.from_dicts(metadata_dict,
condition=FilterCondition.OR)
)
#
response = query_engine.query(query)
return response
#
#llamiondex FunctionTool wraps any python function we feed it
vector_query_tool = FunctionTool.from_defaults(name=f"vector_tool_{name}",
fn=vector_query)
# Prepare Summary Tool
summary_index = SummaryIndex(nodes)
summary_query_engine = summary_index.as_query_engine(response_mode="tree_summarize",
se_async=True,)
summary_query_tool = QueryEngineTool.from_defaults(name=f"summary_tool_{name}",
query_engine=summary_query_engine,
description=("Use ONLY IF you want to get a holistic summary of the documents."
"DO NOT USE if you have specified questions over the documents."))测试 LLM :
response = llm.predict_and_call([vector_query_tool],
"Summarize the content in page number 2",
verbose=True)
######################RESPONSE###########################
=== Calling Function ===
Calling function: vector_tool_BERT_arxiv with args: {"query": "summarize content", "page_numbers": ["2"]}
=== Function Output ===
The content discusses the use of RAG models for knowledge-intensive generation tasks, such as MS-MARCO and Jeopardy question generation, showing that the models produce more factual, specific, and diverse responses compared to a BART baseline. The models also perform well in FEVER fact verification, achieving results close to state-of-the-art pipeline models. Additionally, the models demonstrate the ability to update their knowledge as the world changes by replacing the non-parametric memory.辅助函数用于为所有文档生成 Vectorstore 工具和摘要工具
def get_doc_tools(file_path:str,name:str)->str:
'''
get vector query and sumnmary query tools from a document
'''
#load documents
documents = SimpleDirectoryReader(input_files = [file_path]).load_data()
print(f"length of nodes")
splitter = SentenceSplitter(chunk_size=1024,chunk_overlap=100)
nodes = splitter.get_nodes_from_documents(documents)
print(f"Length of nodes : {len(nodes)}")
#instantiate Vectorstore
vector_index = VectorStoreIndex(nodes,storage_context=storage_context)
vector_index.storage_context.vector_store.persist(persist_path="/content/chroma_db")
#
# Define Vectorstore Autoretrieval tool
def vector_query(query:str,page_numbers:Optional[List[str]]=None)->str:
'''
perform vector search over index on
query(str): query string needs to be embedded
page_numbers(List[str]): list of page numbers to be retrieved,
leave blank if we want to perform a vector search over all pages
'''
page_numbers = page_numbers or []
metadata_dict = [{"key":'page_label',"value":p} for p in page_numbers]
#
query_engine = vector_index.as_query_engine(similarity_top_k =2,
filters = MetadataFilters.from_dicts(metadata_dict,
condition=FilterCondition.OR)
)
#
response = query_engine.query(query)
return response
#
#llamiondex FunctionTool wraps any python function we feed it
vector_query_tool = FunctionTool.from_defaults(name=f"vector_tool_{name}",
fn=vector_query)
# Prepare Summary Tool
summary_index = SummaryIndex(nodes)
summary_query_engine = summary_index.as_query_engine(response_mode="tree_summarize",
se_async=True,)
summary_query_tool = QueryEngineTool.from_defaults(name=f"summary_tool_{name}",
query_engine=summary_query_engine,
description=("Use ONLY IF you want to get a holistic summary of the documents."
"DO NOT USE if you have specified questions over the documents."))
return vector_query_tool,summary_query_tool准备具有指定文档名称的输入列表:
import os
root_path = "/content/data"
file_name = []
file_path = []
for files in os.listdir(root_path):
if file.endswith(".pdf"):
file_name.append(files.split(".")[0])
file_path.append(os.path.join(root_path,file))
#
print(file_name)
print(file_path)
################################RESPONSE###############################
['self_rag_arxiv', 'crag_arxiv', 'RAG_arxiv', '', 'BERT_arxiv']
['/content/data/BERT_arxiv.pdf',
'/content/data/BERT_arxiv.pdf',
'/content/data/BERT_arxiv.pdf',
'/content/data/BERT_arxiv.pdf',
'/content/data/BERT_arxiv.pdf']注意:FunctionTool 期望工具名称的字符串与模式 ‘^[a-zA-Z0–9_-]+$’ 匹配
为每个文档生成矢量工具和摘要工具
papers_to_tools_dict = {}
for name,filename in zip(file_name,file_path):
vector_query_tool,summary_query_tool = get_doc_tools(filename,name)
papers_to_tools_dict[name] = [vector_query_tool,summary_query_tool]
####################RESPONSE###########################
length of nodes
Length of nodes : 28
length of nodes
Length of nodes : 28
length of nodes
Length of nodes : 28
length of nodes
Length of nodes : 28
length of nodes
Length of nodes : 28将工具放入平面列表中
initial_tools = [t for f in file_name for t in papers_to_tools_dict[f]]
initial_tools在 LLM 提示中塞入太多工具选择将导致以下问题:
- 这些工具可能不适合提示,特别是当我们的文档数量很大时,因为我们将每个文档建模为单独的工具。
- 由于 token 数量的增加,成本和延迟将会激增。
- 提示大纲也可能令人困惑,导致 LLM 无法按照指示进行。
这里的解决方案是在工具级别执行 RAG。为了执行此操作,我们将使用 Llama-Index 的 ObjectIndex 类。
该类ObjectIndex允许对任意 Python 对象进行索引。因此,它非常灵活,适用于广泛的用例。例如:
这VectorStoreIndex是 LlamaIndex 的一个关键组件,有助于存储和检索数据。它的工作原理如下:
- 接受对象列表
Node并根据它们构建索引。 - 使用不同的向量存储作为存储后端,增强应用程序的灵活性和可扩展性。
from llama_index.core import VectorStoreIndex
from llama_index.core.objects import ObjectIndex
#
obj_index = ObjectIndex.from_objects(initial_tools,index_cls=VectorStoreIndex)
#将 ObjectIndex 设置为检索器
obj_retriever = obj_index.as_retriever(similarity_top_k=2)
tools = obj_retriever.retrieve("compare and contrast the papers self rag and corrective rag")
#
print(tools[0].metadata)
print(tools[1].metadata)
###################################RESPONSE###########################
ToolMetadata(description='Use ONLY IF you want to get a holistic summary of the documents.DO NOT USE if you have specified questions over the documents.', name='summary_tool_self_rag_arxiv', fn_schema=<class 'llama_index.core.tools.types.DefaultToolFnSchema'>, return_direct=False)
ToolMetadata(description='vector_tool_self_rag_arxiv(query: str, page_numbers: Optional[List[str]] = None) -> str\n\n perform vector search over index on\n query(str): query string needs to be embedded\n page_numbers(List[str]): list of page numbers to be retrieved,\n leave blank if we want to perform a vector search over all pages\n ', name='vector_tool_self_rag_arxiv', fn_schema=<class 'pydantic.v1.main.vector_tool_self_rag_arxiv'>, return_direct=False)设置 RAG 代理
from llama_index.core.agent import FunctionCallingAgentWorker
from llama_index.core.agent import AgentRunner
#
agent_worker = FunctionCallingAgentWorker.from_tools(tool_retriever=obj_retriever,
llm=llm,
system_prompt="""You are an agent designed to answer queries over a set of given papers.
Please always use the tools provided to answer a question.Do not rely on prior knowledge.""",
verbose=True)
agent = AgentRunner(agent_worker)询问问题 1
#
response = agent.query("Compare and contrast self rag and crag.")
print(str(response))
##############################RESPONSE###################################
Added user message to memory: Compare and contrast self rag and crag.
=== LLM Response ===
Sure, I'd be happy to help you understand the differences between Self RAG and CRAG, based on the functions provided to me.
Self RAG (Retrieval-Augmented Generation) is a method where the model generates a holistic summary of the documents provided as input. It's important to note that this method should only be used if you want a general summary of the documents, and not if you have specific questions over the documents.
On the other hand, CRAG (Contrastive Retrieval-Augmented Generation) is also a method for generating a holistic summary of the documents. The key difference between CRAG and Self RAG is not explicitly clear from the functions provided. However, the name suggests that CRAG might use a contrastive approach in its retrieval process, which could potentially lead to a summary that highlights the differences and similarities between the documents more effectively.
Again, it's crucial to remember that both of these methods should only be used for a holistic summary, and not for answering specific questions over the documents.询问问题 2
response = agent.query("Summarize the paper corrective RAG.")
print(str(response))
###############################RESPONSE#######################
Added user message to memory: Summarize the paper corrective RAG.
=== Calling Function ===
Calling function: summary_tool_RAG_arxiv with args: {"input": "corrective RAG"}
=== Function Output ===
The corrective RAG approach is a method used to address issues or errors in a system by categorizing them into three levels: Red, Amber, and Green. Red signifies critical problems that need immediate attention, Amber indicates issues that require monitoring or action in the near future, and Green represents no significant concerns. This approach helps prioritize and manage corrective actions effectively based on the severity of the identified issues.
=== LLM Response ===
The corrective RAG approach categorizes issues into Red, Amber, and Green levels to prioritize and manage corrective actions effectively based on severity. Red signifies critical problems needing immediate attention, Amber requires monitoring or action soon, and Green indicates no significant concerns.
assistant: The corrective RAG approach categorizes issues into Red, Amber, and Green levels to prioritize and manage corrective actions effectively based on severity. Red signifies critical problems needing immediate attention, Amber requires monitoring or action soon, and Green indicates no significant concerns.结论
与标准 RAG 管道(适用于对几个文档进行简单查询)不同,这种智能方法会根据初步发现进行调整,以增强进一步的数据检索。在这里,我们开发了一个自主研究代理,增强了我们全面处理和分析数据的能力。


